Your cart is currently empty!
Blog
-
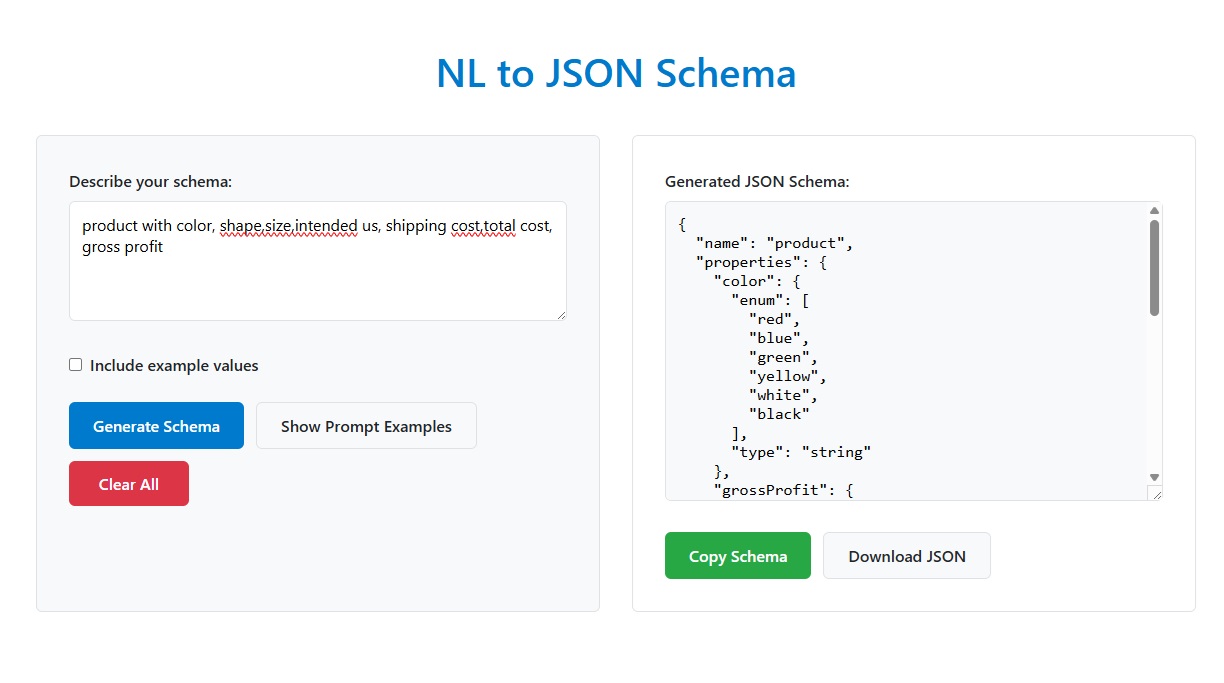
Turn English into JSON Schema, Instantly and Offline
If you’re a developer dealing with APIs or data validation, you know the drill: you need a JSON Schema, and your product manager slacks you something like, “We need a user object with a name, email, age, and a list of favorite colors.”
Then you open VS Code, hit a JSON Schema playground, or use an online generator. It’s still manual, takes time, can lead to errors, and frankly, it’s boring.
Imagine just pasting that message and getting a valid, production-ready JSON Schema. No markdown, no syntax errors, no guesswork.
That’s what this little tool does, and it works completely offline.
What It Is
This project is a local app with a simple interface that converts plain English into precise, standards-compliant JSON Schema. It uses a small, efficient AI model (TinyLlama) that runs entirely on your machine.
It includes:
- TinyLlama: The AI model runs locally using
llama.cpp—no internet needed. - Slick Interface: A clean desktop app built with
pywebviewandFlask. - Smart Parser: It strips markdown, fixes messed-up JSON, and gives you clean, usable output.
- Self-Contained: You can bundle it as an
.exeand run it anywhere.
Just describe your data, and it delivers a full JSON Schema (Draft-07 format) without sending anything to the cloud.
Why You’ll Want It
This tool is for:
- Developers who are tired of writing or figuring out JSON Schema syntax by hand.
- Privacy-conscious teams who need offline tools for secure work.
- Speed fanatics who want fast, ready-to-use schemas from descriptions.
- Automation builders who generate schemas programmatically for workflows, APIs, or AI pipelines.
It’s particularly useful for:
- API prototyping
- Building form validation engines
- AI tools that need structured output
- Data ingestion pipelines
Since it runs locally with TinyLlama and
llama.cpp, it’s quick and respects your computer’s resources and your privacy.
How It Works (Behind the Scenes)
The system works like this:
gui.py: Starts a local Flask server and shows the app in a desktop window usingpywebview.schema_builder.py: Sends your English description to a parsing function.nlpparser.py:- Loads the local TinyLlama model.
- Sends your description with a strict JSON Schema prompt.
- Pulls out the first valid JSON block (even if the model adds extra text).
- Cleans up any markdown or formatting.
- Tries to fix any malformed JSON if necessary.
The result? Clean, Draft-07 compliant JSON Schema.
No ChatGPT. No APIs. Just your computer doing the work.
Example
Input:
“A product has a name (string), price (number), and availability status (boolean).”
Output:
JSON
{ "type": "object", "properties": { "name": { "type": "string" }, "price": { "type": "number" }, "availability": { "type": "boolean" } }, "required": ["name", "price", "availability"] }
In Short
This app transforms your plain English into clean, structured JSON Schema, offline, fast, and reliable.
If you build APIs, forms, or anything that needs data validation, this will save you time and effort.
Want a custom solution built for you or need some fresh eyes on your automations or systems? Please, reach out and let’s chat.
https://automatetowin.com/contact-us - TinyLlama: The AI model runs locally using
-
Clickbait ‘Research’ claims GPT causes brain rot.
Welcome to 2025 where the sources are made up, the science is weak, and peer review doesn’t exist if the peeked result is ‘scary’.
MIT Media Lab, arXiv:2506.08872
This study has been making the rounds on LinkedIn, X, and Facebook. It’s being parroted by the kind of people who see a heatmap and think they’ve discovered God. I read the study. I read the methodology. I read the EEG data. And I’m here to explain, in clear language, why this is not science, it’s narrative engineering.
If you’re sharing this paper as evidence of “ChatGPT causing brain rot,” you’re falling for scientific theater dressed up in academic branding.
1. Sample Size is Statistically Meaningless
The entire study hinges on 54 participants across three groups. Only 18 completed the full cycle including Session 4. These are MIT and Boston-area students, which means it’s already a culturally and academically skewed population. This is not generalizable.
“We recruited a total of 54 participants… 18 participants among them completed session 4.”
Section: AbstractIn neuroscience, and especially in EEG work, small sample sizes are a red flag. Brain signals vary massively between individuals. That’s why robust cognitive EEG studies need large participant pools and replication across multiple environments to mean anything. None of that is present here.
2. EEG is Misused and Misinterpreted
They used the Enobio 32-channel EEG headset. While decent for entry-level neuroscience, it is not remotely close to clinical-grade equipment for what they’re claiming to measure.
They analyzed differences in brainwave patterns—alpha, beta, theta, delta bands—and concluded that LLM users had “less neural engagement.”
“LLM assistance elicited the weakest overall coupling.”
Section: AbstractThat’s not a conclusion, that’s an assumption. Lower EEG activity doesn’t automatically mean “bad.” It could mean improved efficiency, familiarity, or reduced stress. The authors lean into a bias: less effort = less intelligence. That is neither proven nor even well-argued in the data.
3. Overreach on Cognitive Load and “Debt”
They invent the term “cognitive debt” and attempt to position it as a real measurable outcome. It’s not. It’s marketing language that sounds technical. Nowhere in the study is “cognitive debt” defined in a mathematically or scientifically rigorous way.
They rely on EEG band correlations and vague metrics like “ownership of essay” and “ability to quote” to imply that using ChatGPT damages your ability to retain knowledge. But there is no proven causal mechanism, and certainly no long-term follow-up to back that up.
“LLM group… fell behind in their ability to quote from the essays they wrote just minutes prior.”
Section: AbstractWhat they’re describing is short-term recall of an essay you barely wrote with your own hands. That’s not news. If you ask someone to read a legal contract generated by someone else, then recall it word for word five minutes later, the same issue arises. This isn’t about AI. It’s about task ownership.
4. Emotional Language is Not Science
The paper contains emotionally charged phrases like:
- “We stopped early because the findings were too striking.”
- “Cognitive offloading leads to deficiency.”
- “It was too scary not to publish.”
Fear is not a scientific outcome. This is not a measured response based on falsifiable results. It is narrative crafting designed to trigger sharing and debate on social platforms. And it worked.
Scientific conclusions must be replicable, not reactionary. This is not the language of research. It is the language of clickbait.
5. The Experimental Conditions Were Flawed
Participants were assigned to one of three groups:
- Group 1: LLM-only (ChatGPT)
- Group 2: Search Engine (Google)
- Group 3: Brain-only (no tools)
Each participant wrote essays using prompts pulled from SAT questions. They then swapped conditions in Session 4, which the authors use to compare cognitive state shifts.
But here’s the problem: The control variables weren’t held constant. Participants were not equally experienced with the tools. Some were first-time ChatGPT users. Others were seasoned. Some used LLMs to translate foreign languages. Others used it to bypass writing entirely.
“Some participants used LLM for translation.”
Summary Table, Page 3This is not a controlled study. It’s a user-behavior diary pretending to be neuroscience.
6. Scoring Was Subjective and Internally Reinforced
They used an “AI judge” to grade the essays. Let’s be clear: they used another LLM to score LLM-generated work, then compared it to human scoring. This is not a valid cross-check! It’s a recursive loop.
“We performed scoring with the help from the human teachers and an AI judge (a specially built AI agent).”
AbstractThere is no external validation set. There is no independent scoring system. The outcomes were shaped by the very biases embedded in the original tools they were supposed to test.
7. The “Ownership” and “Quoting” Metrics are Built to Fail
The study found that LLM users were less able to quote their essays or felt lower “ownership.” That’s expected. If the AI generates the structure, content, and phrasing, you’re not going to remember it as well. But this isn’t cognitive damage, it’s basic memory encoding.
They position this as a failure state, but it’s actually a feature. Cognitive offloading is the entire point of using tools. We don’t remember phone numbers because we use contact lists. That doesn’t mean our brains are rotting!!! It means we are prioritizing higher-order tasks and offloading the minutiae.
8. No Real Peer Review
This is a preprint on arXiv. It has not passed formal peer review. Yet it’s being shared on social media as if it’s a settled fact. People are reposting it with captions like “Proof that AI is making us stupid,” despite the obvious limitations and speculative leaps.
Summary: What This Actually Is
This study is not worthless. It’s just not what it claims to be. At best, it’s exploratory research on how different toolsets affect short-term engagement with a writing task. At worst, it’s a content-marketing campaign in the skin of science.
The emotional charge, early stoppage, invented terminology, and tiny sample size all point to one thing: this was designed to be viral, not rigorous.
Final Thought
If you’re worried about ChatGPT “damaging brains,” this study is not your proof. It’s a hypothesis, dressed up like a conclusion, passed around by people who haven’t read it.
If you want to talk about real risks of LLMs, we can talk about bias replication, dependency, epistemic narrowing, or training data ethics. But this paper isn’t it. This is theater.
If anyone needs help understanding what real science looks like, I’ll be here.